기업 AI 보안 가이드라인은 AI 도입을 늦추는 문서가 아니라, 업무 활용을 더 빠르고 안전하게 확산시키기 위한 운영 기준입니다. 특히 AI 데이터 보호 및 접근 통제, 권한 설계, 로그, 반출 통제, 승인 절차를 기존 보안 체계에 통합해야 실제 효과가 납니다.
이 글은 사내 규정, 체크리스트, 교육 자료의 뼈대를 바로 만들 수 있도록 핵심 구조와 실무 적용 포인트를 한 번에 정리한 문서입니다.
목차
- 1. 기업 AI 보안 가이드라인의 기본 구조
- 2. AI 데이터 보호 및 접근 통제 설계 원칙
- 3. 접근 통제 모델: 계정, 권한, 네트워크
- 4. AI 로그 관리와 사용 승인 절차
- 5. 데이터 반출 통제와 DLP, 규제 준수
- 6. 내부통제, 사례, 교육, 실행 로드맵
- 7. 부록 A. AI 보안 체크리스트
- 8. 부록 B. 정책 문구 샘플
1. 기업 AI 보안 가이드라인의 기본 구조
임직원이 이미 다양한 생성형 AI를 업무에 쓰는 지금, 기업 AI 보안 가이드라인 없이 버티는 조직은 드뭅니다. ChatGPT, Copilot, 국내 LLM, 코드 어시스턴트가 개발·기획·마케팅·고객센터까지 퍼졌지만, 많은 회사의 규정은 여전히 이메일·파일서버·메신저 중심에 머물러 있습니다.
그래서 AI 데이터 보호 및 접근 통제 같은 핵심 통제가 비어 있는 경우가 많습니다. 특히 프롬프트 입력, 로그 저장, 모델 재학습, 외부 SaaS 업로드는 기존 규정만으로 다루기 어렵습니다. Cyberhaven의 AI security best practices와 AI 데이터 반출 자료는 복사·붙여넣기와 잘게 쪼개진 프롬프트 형태의 유출이 기존 파일 중심 통제의 사각지대가 될 수 있다고 설명합니다.
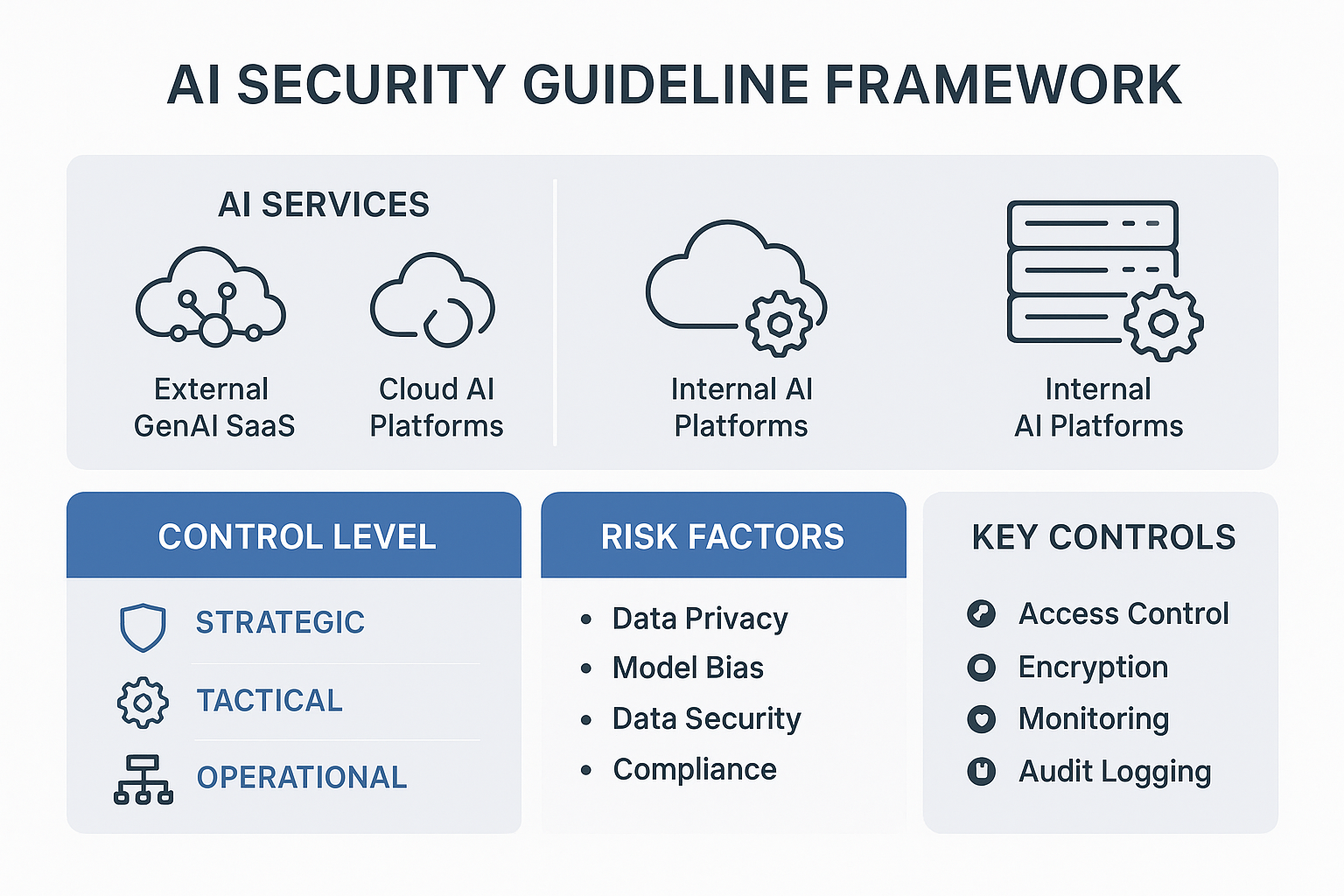
먼저 무엇을 통제할지 범위를 나눠야 합니다. 외부 GenAI SaaS, 클라우드 AI 플랫폼, 사내 AI 플랫폼은 통제권과 책임이 서로 다르기 때문입니다. 이 구분이 없으면 승인, 로그, DLP, 규제 검토가 모두 흐려집니다.
| AI 서비스 유형 | 예시 | 통제권 | 주요 리스크 | 핵심 통제 |
|---|---|---|---|---|
| 외부 GenAI SaaS | ChatGPT, Copilot 웹 | 낮음 | 국외 이전, 재학습, 로그 한계 | 업로드 제한, CASB, 승인제 |
| 클라우드 AI 플랫폼 | Azure OpenAI, Vertex AI | 중간 | API 키, 네트워크, 리전 | RBAC, Private Endpoint, 로깅 |
| 사내 AI 플랫폼 | 사내 LLM, RAG 포털 | 높음 | 운영자 권한, 인프라 보안 | 망분리, 데이터 소스 통제, 감사 |
이 가이드라인은 다음 6대 도메인으로 묶으면 관리가 쉽습니다.
- AI 데이터 보호 및 접근 통제
- 모델·플랫폼 보안
- AI 로그 관리와 감사
- AI 사용 승인 절차
- AI DLP와 데이터 반출 통제
- 교육·기업 AI 거버넌스
상위 기준도 함께 연결해야 합니다. IC3 공동 권고 PDF는 AI를 기존 보안 구조와 분리하지 말고 통합하라고 권고하며, 기본값을 보수적으로 두고 벤더·공급망 위험을 사전 평가하라고 강조합니다.
실무적으로는 문서가 거창할 필요가 없습니다. 중요한 것은 정책 문구가 실제 승인, 차단, 로그, 교육으로 이어질 정도로 구체적이어야 한다는 점입니다.
2. AI 데이터 보호 및 접근 통제 설계 원칙
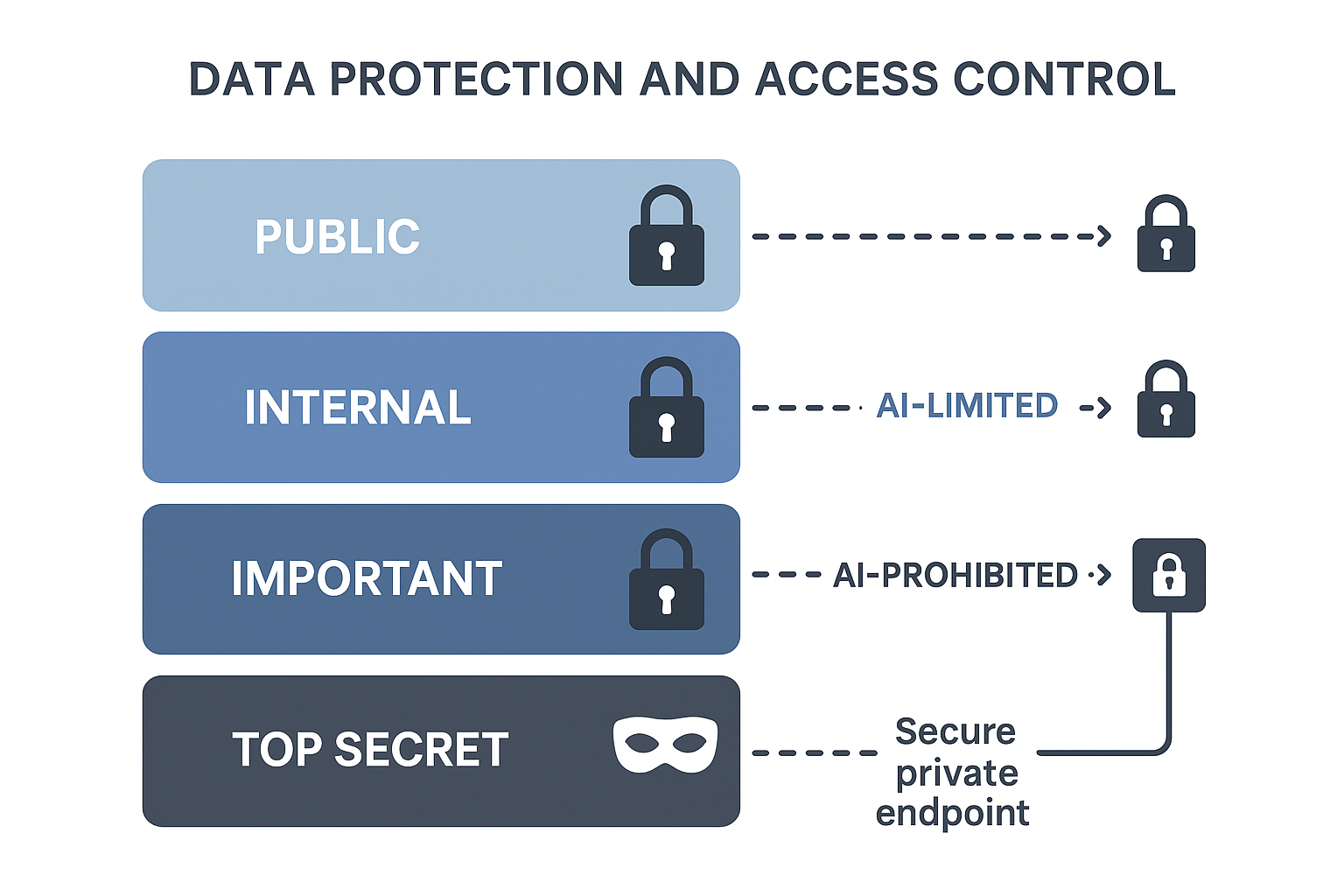
핵심은 기존 데이터 분류 체계에 AI 사용 가능 여부를 붙이는 것입니다. 단순히 공개·내부·중요·극비만으로는 실제 운영이 어렵습니다. 여기에 AI-허용, AI-제한, AI-금지 태그를 추가해야 현업과 보안팀이 같은 기준으로 움직일 수 있습니다.
| 데이터 등급 | AI 태그 | 사용 기준 |
|---|---|---|
| 공개 | AI-허용 | 승인된 환경에서 사용 가능 |
| 내부 | AI-제한 | 사내 AI 플랫폼 우선, 마스킹 필요 |
| 중요 | AI-제한 | 목적 승인, 제한된 역할만 허용 |
| 극비 | AI-금지 | 외부·내부 AI 직접 업로드 금지 |
업로드 금지 데이터는 문장으로 못 박아야 합니다. 개인정보, 고객 계약서, 미공개 재무 자료, 핵심 소스코드, 접근키, 소송 문서는 원칙적으로 금지 대상입니다. Knostic는 데이터 카탈로그에 AI 사용 허용 범위를 메타데이터로 넣고 데이터 소유자가 승인하는 방식을 제안합니다. 자세한 구조는 AI data governance에서 참고할 수 있습니다.
여기에 최소 권한 원칙, RBAC, 목적 기반 접근 통제를 결합합니다. 예를 들어 데이터셋마다 학습 가능, 추론만 가능, 교육 예제 금지처럼 허용 목적과 금지 목적을 따로 적는 방식이 효과적입니다.
저장·전송 보호도 빠질 수 없습니다. 학습 데이터, 벡터DB, 프롬프트 로그, 결과 저장소는 암호화하고 KMS 기반으로 키를 관리해야 합니다. 전송 구간은 TLS 1.2 이상을 기본으로 하고, 가능하면 Private Endpoint나 VPC 연결을 사용하는 편이 안전합니다. 또한 SaaS형 AI는 고객 데이터 재학습 옵션, 저장 기간, 삭제 요청 방법, 서브프로세서 범위를 반드시 확인해야 합니다. Cyberhaven은 이와 관련한 위험을 해당 보안 가이드에서 짚고 있습니다.
마지막으로 데이터 마스킹과 익명화는 교육만으로 끝내면 안 됩니다. 이름은 고객 A, 연락처는 일반화 표기, 계좌·카드번호는 중간 자리 마스킹을 기본 예시로 제시하세요. 개발·테스트 환경에서는 실데이터를 금지하고, 익명화된 샘플만 쓰는 원칙을 넣어야 합니다.
3. 접근 통제 모델: 계정, 권한, 네트워크
업무용 AI는 모두 회사 계정으로만 접근하게 해야 합니다. 개인 계정 사용을 허용하면 퇴사자 회수, 감사, 로그 연계가 모두 무너집니다. 따라서 SSO와 IdP 연동을 기본으로 하고, 관리자 콘솔·API 키 화면·데이터 소스 연결 화면에는 MFA를 강제해야 합니다.
외부 협력사 계정은 EXT_ 접두어, 만료일, 분리 로그를 기본값으로 두는 편이 안전합니다. 권한은 다음과 같은 3단계 모델이 실무적으로 가장 다루기 쉽습니다.
| 역할 | 허용 범위 | 제한 사항 |
|---|---|---|
| 일반 사용자 | 승인된 프롬프트, 제한된 데이터 조회 | 임의 데이터 연결 불가 |
| 파워 유저/개발자 | 워크플로우 구성, 일부 데이터 소스 연결 | 정책 변경 불가 |
| 관리자 | 정책 변경, 권한 부여, 커넥터 관리 | 최소 인원만 지정 |
Joiner/Mover/Leaver 프로세스에도 AI 권한을 넣어야 합니다. 인사 시스템의 발령 정보가 IdP 그룹으로 연결되고, 그 그룹이 AI 플랫폼 권한으로 자동 반영되도록 설계하면 누락을 줄일 수 있습니다.
네트워크도 함께 봐야 합니다. JDSupra는 엔터프라이즈 AI에서 네트워크와 접근 통제를 분리해서 보면 안 된다고 설명합니다. 관련 내용은 AI security and access controls best practices에서 확인할 수 있습니다. 사내 AI 플랫폼은 VPN 또는 제로트러스트 인증 단말만 접근 허용, 관리 콘솔은 관리자망 분리, 외부 SaaS AI는 CASB나 프록시로 도메인·업로드 정책을 제어하는 방식이 현실적입니다.
Shadow AI 탐지도 이 구간에서 함께 해야 합니다. 승인되지 않은 AI 도구 접속과 비인가 플러그인 사용은 접근 통제와 DLP가 만나는 지점이기 때문입니다.

4. AI 로그 관리와 사용 승인 절차
AI 로그 관리의 목적은 누가, 언제, 무엇을 질문했고, 어떤 데이터에 접근했는가를 나중에 설명할 수 있게 만드는 것입니다. Liminal은 엔터프라이즈 AI 거버넌스에서 사용자 ID, 부서, 역할, 접속 IP, 서비스·모델·엔드포인트, 시간, 프롬프트 또는 요약본, 참조 데이터 소스, 결과 요약, 권한 변경, API 키 이력 같은 항목을 남기라고 제안합니다. 자세한 항목은 Enterprise AI governance guide에서 참고할 수 있습니다.
프롬프트와 응답 원문은 개인정보·기밀성 이슈가 있으므로 저장 범위를 정해야 합니다. 원문이 어렵다면 요약, 해시, 민감정보 제거본이라도 남겨야 합니다. 로그 보존은 내부 감사 주기와 개인정보 포함 여부를 고려해 정하고, 읽기 권한은 보안·감사·개인정보 담당자로 최소화해야 합니다.
이상 행위 탐지는 기존 SIEM·UEBA와 붙여야 효과가 큽니다. 짧은 시간 민감 키워드 반복 질의, 특정 프로젝트 데이터 과다 조회, 야간 대량 질의, 관리자 기능 접근 시도는 대표 탐지 규칙입니다.
실무형 승인 절차 설계
신규 서비스는 AI 서비스 도입 평가를 거쳐야 합니다. 평가 항목은 보안·인프라, 데이터 처리·프라이버시, 접근 통제, 로깅·감사 4블록으로 나누면 관리가 쉽습니다. 승인 기준도 단순한 예·아니오보다 승인, 보완, 불허로 두는 편이 실무적입니다.
이후 AI 온보딩 프로세스는 신청 → 상급자 검토 → 보안·개인정보·법무 검토 → 계정 발급 → 교육 이수 순으로 고정하세요. 승인서에는 사용 목적, 부서, 데이터 등급, 파일 업로드 허용 범위, 소스코드 허용 범위, 예상 이용량을 꼭 넣어야 합니다.
로그는 단순 저장이 아니라 사후 설명 가능성을 확보하는 장치입니다. 승인 절차는 단순 통과가 아니라 누가 어떤 조건으로 AI를 쓰는지 문서화하는 장치입니다.
5. 데이터 반출 통제와 DLP, 규제 준수
AI 시대의 반출은 파일 첨부만이 아닙니다. 내부 문서나 코드 전체를 프롬프트에 붙여넣는 직접 반출, 기밀 내용을 AI가 다시 써준 결과물을 외부에 보내는 간접 반출이 모두 문제입니다. Cyberhaven은 이런 유형이 기존 보안 프로그램의 사각지대가 될 수 있다고 AI data exfiltration 자료에서 지적합니다.
기술 통제는 세 가지가 핵심입니다.
- AI DLP: 특정 GenAI 도메인으로 나가는 텍스트·파일 검사
- 프록시/브라우저 제어: 주민번호, 계좌번호, 내부 코드명 탐지
- 사내 전용 AI 포털: 외부 AI는 예외 승인제로 운영
정책 문구도 구체적이어야 합니다. 개인정보, 고객 기밀 문서, 소스코드 전체 파일, 접근키와 토큰은 외부 AI 서비스에 직접 업로드할 수 없다처럼 금지 대상을 적시해야 합니다. 위반 시에는 정보보호 규정과 인사 규정에 연결하고, 사고 시에는 즉시 신고 → 영향 분석 → 제공사 삭제 요청 → 재발 방지 조치 순으로 움직이게 해야 합니다.
개인정보보호 측면에서는 외부 AI SaaS 사용이 개인정보 처리 위탁, 공동관리, 국외 이전 이슈와 연결될 수 있습니다. 사업자의 역할, 저장 위치, 처리 목적 결정 권한, 하위 위탁 범위를 계약서로 정리해야 합니다. 또한 데이터 최소화와 목적 제한을 실제 사례로 써야 합니다.
- 고객센터는 이름·연락처 제거 후 요약만 전달
- 개발팀은 계정 ID 대신 난수 ID 사용
- 마케팅은 계약서 전체 대신 필요한 문단만 발췌
데이터 주체 권리 대응을 위해서는 특정 식별자로 프롬프트·로그를 검색하고 삭제할 수 있는 구조도 필요합니다.
6. 내부통제, 사례, 교육, 실행 로드맵
문서 체계는 3층으로 가면 됩니다. 최상위는 기업 AI 보안 가이드라인, 그 아래는 세부 지침, 마지막은 운영 절차서입니다. 규정에는 목적·적용 범위·원칙을, 지침에는 데이터 분류·권한·로그·DLP 기준을, 절차서에는 계정 신청·신규 서비스 심사·사고 보고 양식을 넣습니다.
정기 점검은 연 1회 이상 실시하고, Liminal이 강조하듯 정책 적용 여부, 민감 데이터 업로드 차단 결과, Shadow AI 탐지, 권한 오남용, 교육 이수율을 함께 확인해야 합니다.
| 부서 | 핵심 체크 포인트 |
|---|---|
| 개발팀 | 코드 업로드 범위, 재학습 옵트아웃, 리포지토리 AI 태그, 라이선스 검토, IDE 로그 연동 |
| 고객센터 | PII 제거, 자동 마스킹, 응답 검수, 전용 워크스페이스, 분쟁 대비 로그 보존 |
| 임원진 | 극비 자료 AI-금지, 민감 내용 제거 후 사용, 사내 포털 우선, 별도 감사 강화 |
교육은 보안, 개인정보, AI 윤리를 따로 떼지 말고 통합하는 편이 낫습니다. 연 1회 이상 필수 교육으로 편성하고, 기업 AI 보안 가이드라인 핵심 요약, 실제 사고 사례, 안전한 프롬프트 작성, 마스킹 실습을 넣으세요.
FAQ 포털에는 허용 도구 목록, 업로드 가능·금지 예시, 부서별 템플릿, 신고 채널을 모아 두면 좋습니다. 실수 신고는 핫라인, 전용 메일, 익명 폼처럼 여러 경로를 두고, 언제 어떤 서비스에 어떤 유형 데이터를 올렸는지만 빠르게 적게 해야 합니다.
실행 로드맵
| 단계 | 핵심 작업 | 책임 부서 | 산출물 |
|---|---|---|---|
| 0단계 | Shadow AI 포함 현황 파악 | IT·보안 | 사용 도구 인벤토리 |
| 1단계 | 가이드라인 초안 수립 | 보안·개인정보·법무 | 규정·체크리스트 |
| 2단계 | 파일럿 적용 | 현업 부서·IT | 개선 의견, 통제 보완안 |
| 3단계 | 전사 확대·제도화 | 경영진·보안·HR | 교육, 감사, 보고 체계 |
기업 AI 보안 가이드라인은 AI 도입을 늦추는 문서가 아닙니다. 오히려 AI 데이터 보호 및 접근 통제를 먼저 설계해 더 빠르고 안전하게 확산시키는 운영 기준입니다. 이 글의 목차를 그대로 사내 문서 목차로 옮기고, 각 부서 환경에 맞게 채워 넣으면 바로 실행 가능한 초안을 만들 수 있습니다.
7. 부록 A. AI 보안 체크리스트
- 도입 전 점검: 저장 위치, 재학습 여부, 국외 이전, SSO, RBAC, 로그 제공 여부 확인
- 일상 사용 점검: AI-허용 범위 확인, 민감정보 마스킹, 회사 계정만 사용
- 사고 대응 점검: 업로드 시점·데이터 확인, 삭제 요청, 로그 확보, 영향 분석 수행
8. 부록 B. 정책 문구 샘플
- 개인정보 및 회사·고객의 기밀 정보는 사전 승인 없이 외부 AI 서비스에 업로드할 수 없다.
- AI 서비스 사용 로그는 최소 1년 이상 보존하며, 로그 접근은 보안·감사·개인정보보호 담당자로 제한한다.
- AI 플랫폼 관리자 권한은 최소 인원에 한해 부여하며, 모든 권한 변경은 감사 로그로 기록한다.
자주 묻는 질문 (FAQ)
기업 AI 보안 가이드라인은 왜 별도로 필요한가요?
기존 정보보호 규정은 이메일, 파일서버, 메신저 중심으로 설계된 경우가 많아 프롬프트 입력, AI 로그, 모델 재학습, 외부 SaaS 업로드 같은 새로운 위험을 충분히 다루지 못합니다. 따라서 AI 특성을 반영한 별도 가이드라인이 필요합니다.
AI 데이터 보호 및 접근 통제의 첫 단계는 무엇인가요?
가장 먼저 해야 할 일은 기존 데이터 분류 체계에 AI 사용 태그를 붙이는 것입니다. 공개, 내부, 중요, 극비 같은 등급에 AI-허용, AI-제한, AI-금지 태그를 결합해야 실제 업로드 허용 범위와 승인 절차를 운영할 수 있습니다.
기업에서 개인 AI 계정 사용을 막아야 하는 이유는 무엇인가요?
개인 계정을 허용하면 퇴사자 권한 회수, 감사 추적, 로그 연계, 사고 대응이 모두 어려워집니다. 회사 계정 기반의 SSO, IdP, MFA 체계를 강제해야 계정 통제와 증적 관리가 가능합니다.
AI 로그는 어디까지 남겨야 하나요?
최소한 사용자 식별 정보, 접속 시간, 사용한 서비스와 모델, 참조 데이터 소스, 결과 요약, 권한 변경 이력은 남겨야 합니다. 프롬프트와 응답 원문 저장이 어렵다면 요약본이나 민감정보 제거본이라도 보존하는 것이 좋습니다.
외부 생성형 AI 사용 시 가장 먼저 막아야 할 데이터는 무엇인가요?
개인정보, 고객 계약서, 미공개 재무 자료, 핵심 소스코드, 접근키와 토큰, 소송 문서는 우선 금지 대상으로 두는 것이 일반적입니다. 이런 항목은 정책 문구에 명시하고 DLP와 승인 절차로 함께 통제해야 합니다.