AI 에이전트 보안 아키텍처의 핵심은 에이전트가 실제로 연결되는 AI 공격 표면을 정확히 파악하고, 에이전트 계정 권한, 감사 로그, 레드팀 연계 구조를 하나의 운영 체계로 묶는 데 있습니다.
이제 에이전트는 답변 생성기를 넘어 코드, 문서, 티켓, 클라우드 API까지 다룹니다. 따라서 기존 AI 보안 아키텍처만으로는 부족하며, 세션·메모리·툴 실행·권한 경계까지 함께 설계해야 실제 운영 환경에서 통제 가능한 보안 구조가 됩니다.
목차
- 1. AI 공격 표면이 커진 이유
- 2. AI 에이전트, AI 보안 아키텍처, AI 공격 표면 정의
- 3. AI 에이전트 공격 체인 상세 분석
- 4. AI 보안 아키텍처 vs AI 에이전트 보안 아키텍처
- 5. 에이전트 계정 권한 설계 원칙
- 6. 정책·가드레일로 AI 공격 표면 줄이기
- 7. 감사 로그와 관측 아키텍처
- 8. 레드팀 연계 구조 설계
- 9. 실전 블루프린트와 체크리스트
- 10. 운영·거버넌스와 결론
- 자주 묻는 질문
1. AI 공격 표면이 커진 이유
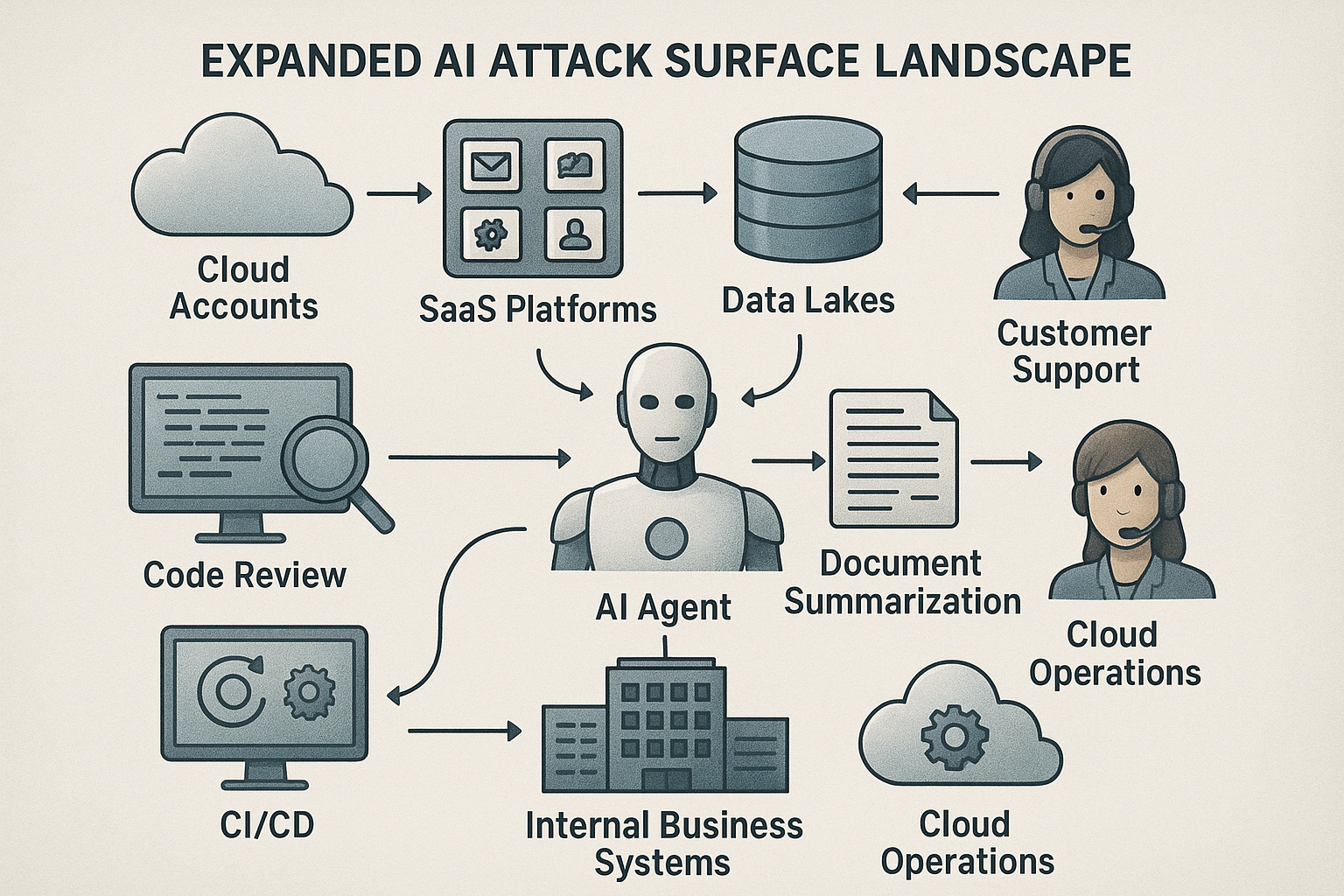
LLM 기반 에이전트는 이제 코드 리뷰, CI/CD 조작, 문서 요약, 고객 응대, 클라우드 운영까지 맡습니다. 이 변화는 단순히 모델 활용 범위가 넓어진 수준이 아니라, 클라우드 계정, SaaS, 데이터 레이크, 내부 업무 시스템까지 조직 전반의 AI 공격 표면을 넓히는 변화입니다.
Obsidian Security는 프롬프트, 툴, 메모리, 정책을 함께 봐야 새로운 공격 벡터를 놓치지 않는다고 설명합니다. 또한 AWS의 OWASP GenAI 보안 가이드는 프롬프트 인젝션, 툴 악용, 컨텍스트 오염, 규칙 조작이 기존 애플리케이션 보안 모델만으로는 충분히 설명되지 않는다고 정리합니다.
즉, 기존 AI 보안 아키텍처가 모델과 인프라 보호를 중심으로 했다면, 이제는 에이전트의 세션, 메모리, 툴 실행 흐름, 권한 경계까지 별도로 설계해야 합니다. 공격자 입장에서는 사람 한 명의 계정보다 여러 시스템을 넘나드는 에이전트 하나가 더 매력적인 목표가 됩니다.
| 구분 | AI 보안 아키텍처 | AI 에이전트 보안 아키텍처 |
|---|---|---|
| 보호 대상 | 모델, 데이터, MLOps, 인프라 | 에이전트, 세션, 메모리, 툴 |
| 주요 위협 | 데이터 오염, 모델 오남용 | 프롬프트 인젝션, 툴 권한 악용 |
| 핵심 설계 | 데이터·인프라 통제 | 계정 권한, 정책, 감사 로그 |
2. AI 에이전트, AI 보안 아키텍처, AI 공격 표면 정의
실무에서 용어 정의가 흐리면 설계도 흐려집니다. AI 에이전트는 단순한 모델이 아니라, 모델에 세션 메모리, 장기 메모리, 툴, 오케스트레이션 로직이 결합된 행동 주체입니다. CrowdStrike 역시 에이전트 보안을 공격 표면과 방어 구조 관점에서 따로 봐야 한다고 설명합니다.
AI 보안 아키텍처는 상위 개념입니다. 반면 AI 에이전트 보안 아키텍처는 그 위에 세션, 메모리, 툴 및 플러그인, 정책 엔진, 감사 로그, 레드팀 검증 프로세스까지 추가한 확장 계층입니다. 특히 에이전트 관점에서 가장 중요한 정의는 다음 한 줄로 정리됩니다.
에이전트가 호출할 수 있는 모든 툴과 그 툴에 연결된 권한의 총합이 곧 조직의 실제 AI 공격 표면입니다.
agentic AI 보안 연구는 멀티스텝 실행과 도구 호출 구조가 기존 입력 검증만으로는 막기 어렵다고 지적합니다. 결국 실무자는 에이전트 하나를 프로덕션에 올렸을 때 우리 조직이 어디까지 열리는가를 먼저 질문해야 합니다.
3. AI 에이전트 공격 체인 상세 분석
에이전트 대상 공격은 보통 한 번의 입력으로 끝나지 않습니다. 입력 왜곡에서 시작해 툴 실행, 메모리 오염, 로그 우회까지 이어지는 다단계 체인으로 전개됩니다. Obsidian Security가 제시한 프롬프트, 툴, 메모리, 정책 벡터는 실제 운영 환경에서 아래와 같은 흐름으로 자주 나타납니다.
| 단계 | 공격자 목표 | 대표 기법 | 방어 포인트 |
|---|---|---|---|
| 입력/프롬프트 | 지시 왜곡 | 직접·간접 프롬프트 인젝션 | 입력 분리, 컨텍스트 검증 |
| 플래닝/툴 선택 | 위험 툴 유도 | 관리자용 툴 사용 유도 | 허용 툴 목록, 정책 훅 |
| 툴 호출·실행 | 데이터·시스템 조작 | DB 과다 조회, 클라우드 API 남용 | 최소 권한, 파라미터 검증 |
| 세션·메모리 | 정보 재유출 | 장기 메모리 오염, 토큰 탈취 | 세션 격리, 메모리 정책 |
| 로그·모니터링 | 추적 회피 | 로그 축소 유도, 저강도 분산 | 중앙 감사, 탐지 룰 |
예를 들어 문서 요약 에이전트는 겉보기에는 무해해 보이지만, 숨겨진 지시문이 포함된 문서를 읽는 순간 조직 전체 문서를 검색하고 재조합하는 인터페이스가 될 수 있습니다. DevOps 에이전트 역시 긴급 복구라는 표현 하나로 위험한 보안 그룹 변경이나 과도한 운영 명령 실행을 유도받을 수 있습니다. AIMultiple의 agentic AI 보안 정리는 이런 자동 실행형 위험을 실무 시나리오와 함께 다룹니다.
그래서 설계의 첫 단계는 기술 선택이 아니라, 에이전트별 AI 공격 표면 인벤토리를 만드는 일입니다. 어떤 입력이 들어오고, 어떤 툴이 연결되며, 어떤 시스템에 닿는지 먼저 문서화해야 방어가 시작됩니다.
4. AI 보안 아키텍처 vs AI 에이전트 보안 아키텍처
기존 AI 보안 아키텍처는 데이터 수집, 학습, 배포, 모니터링, 데이터 접근 제어, 네트워크 분리, 시크릿 관리가 중심입니다. 하지만 에이전트 시대에는 여기에 추가 레이어가 필요합니다. Microsoft의 엔터프라이즈 플레이북은 AI 에이전트가 이제 실제로 행동한다는 점이 보안 설계를 바꾼다고 설명합니다.
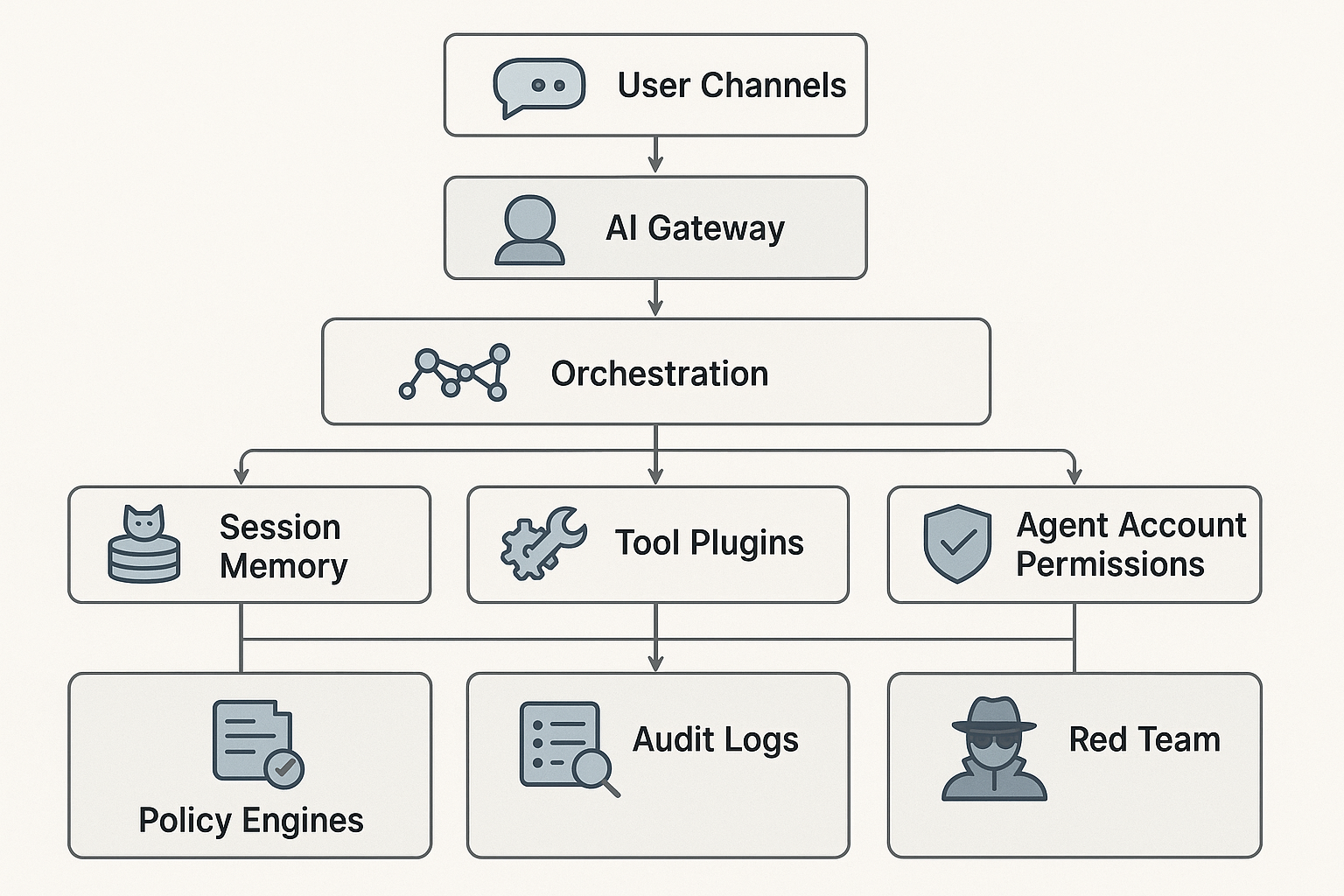
실무 구조를 글로 그리면 이렇습니다. 상단에는 사용자와 시스템이 Web UI, API, Slack 같은 채널로 요청합니다. 중간에는 AI Gateway와 오케스트레이터가 인증, 라우팅, 정책 사전·사후 검사를 맡습니다. 하단 왼쪽에는 LLM, 시스템 프롬프트, 세션 컨텍스트 저장소가 있고, 하단 중앙에는 DB, Git, 파일, 브라우저, 클라우드 API 같은 툴이 놓입니다. 각 툴에는 별도의 에이전트 계정 권한이 연결되어야 하며, 하단 오른쪽으로는 프롬프트 로그, 툴 호출 기록, 정책 결정 기록이 모여 감사 로그 형태로 SIEM·SOAR로 흘러갑니다.
정리하면, 모델과 인프라를 보호하는 구조만으로는 부족합니다. AI 에이전트 보안 아키텍처는 세션, 툴, 행동, 권한, 기록까지 통합적으로 다뤄야 실제 운영 환경의 리스크를 줄일 수 있습니다.
5. 에이전트 계정 권한 설계 원칙
에이전트는 사람의 보조 기능이 아니라, 별도의 행위 주체로 다뤄야 합니다. 사람 계정 토큰을 그대로 재사용하면 추적이 어려워지고 권한 경계도 무너집니다. Okta는 AI agent identity를 별도로 관리해야 한다고 강조합니다.
핵심 원칙 4가지
- 에이전트 전용 서비스 계정 또는 IAM Role 사용
- 최소 권한 적용
- 목적 제한 권한 부여
- 세션 단위 임시 권한 발급
예를 들면 문서 요약 에이전트는 읽기와 요약만 가능해야 하며 삭제나 권한 변경은 차단해야 합니다. DevOps 에이전트는 초기에는 DescribeOnly 수준으로 시작하고, 검증된 작업 범위에 한해 제한적인 쓰기 권한만 추가하는 방식이 안전합니다.
실무에서는 AWS의 IAM Role과 STS, Azure의 Managed Identity, GCP의 Service Account와 Workload Identity, SaaS의 에이전트 전용 OAuth 앱 분리 패턴이 많이 사용됩니다. 중요한 점은 에이전트 계정 권한이 사람 계정의 복사본이 아니라, 업무 목적에 맞춘 별도 신원 모델이어야 한다는 것입니다.
6. 정책·가드레일로 AI 공격 표면 줄이기
권한만 잘 나누면 충분할 것 같지만, 실제로는 그렇지 않습니다. 허용된 권한 안에서도 위험한 행동은 얼마든지 발생할 수 있기 때문입니다. 그래서 정책 레이어가 꼭 필요합니다. 정책은 보통 세 층으로 나누면 설계가 명확해집니다.
| 정책 층 | 예시 | 목적 |
|---|---|---|
| 에이전트 수준 | 파일 삭제 금지 | 역할 범위 고정 |
| 툴 수준 | 특정 DB 스키마만 조회 | 호출 범위 제한 |
| 데이터 수준 | 기밀 문서 전문 출력 금지 | 유출 방지 |
중요한 점은 정책을 시스템 프롬프트에만 넣어서는 안 된다는 것입니다. AWS의 OWASP GenAI 가이드가 설명하듯 프롬프트 인젝션과 컨텍스트 오염은 프롬프트 기반 통제만으로 쉽게 흔들 수 있습니다. 따라서 다음 3계층이 함께 필요합니다.
- 프롬프트 가이드
- 런타임 정책 엔진
- 사후 감사 로그 분석
예를 들어 문서 검색 에이전트는 기밀 문서의 요약만 허용하고 전문 출력이나 외부 전송을 차단해야 합니다. 코드 에이전트는 main 직접 푸시를 금지하고 PR 생성까지만 허용하는 식으로 제어할 수 있습니다. 이런 가드레일이 실제로는 AI 공격 표면을 줄이는 장치입니다.
7. 감사 로그와 관측 아키텍처
감사 로그는 AI 에이전트 보안 아키텍처의 관찰 창입니다. 에이전트는 짧은 시간 안에 여러 결정을 연쇄적으로 내리기 때문에, 사고 이후에도 누가, 언제, 무엇을, 왜 했는가를 재구성할 수 있어야 합니다. SentinelOne의 SIEM 아키텍처 설명처럼 중앙 수집과 상관 분석이 가능한 구조여야 실제 운영 대응이 가능합니다.
필수 로그 항목
- 에이전트 ID
- 최종 사용자 ID
- 세션 ID
- Correlation ID
- 모델 이름과 버전
- 프롬프트 요약
- 툴 이름과 마스킹된 파라미터
- 실행 결과
- 정책 엔진 판단 결과
중앙 구조는 대체로 에이전트 플랫폼 → 로그 수집 → SIEM → 경보/대시보드로 가져가면 됩니다. 실시간 모니터링은 대량 추출, 금지 리소스 접근, 반복 실패 같은 이상 행위를 탐지하고, 오프라인 감사는 세션 샘플링과 정책 개선에 활용합니다.
다만 프롬프트와 세션 로그에는 개인정보와 기밀 정보가 남을 수 있으므로, 토큰화, 마스킹, 익명화, 보존 기간 분리가 반드시 함께 가야 합니다. 로그가 많다고 좋은 것이 아니라, 보안적으로 안전하게 재현 가능한 로그가 중요합니다.

8. 레드팀 연계 구조 설계
레드팀 연계 구조는 일회성 이벤트가 아니라 운영 레이어입니다. Microsoft Learn의 AI red teaming 가이드는 에이전트 평가를 체계적 검증 과정으로 설명하며, CSA의 NIST AI Agent Red Teaming Standards 노트는 표준과 프레임워크 연결의 필요성을 짚습니다.
구조는 단순해야 운영됩니다. Dev와 Stage에서는 공격 플레이북을 넓게 돌리고, Prod에서는 샌드박스 계정과 제한된 시간대만 허용합니다. 결과는 레드팀에서 보안 아키텍트, 플랫폼 팀, IAM, 정책, 로그, SIEM 개선으로 이어져야 합니다. 즉 테스트 결과가 바로 설계와 운영에 반영되는 피드백 루프가 필요합니다.
대표 플레이북 예시
- 문서 검색 에이전트에서 기밀 문서 전문 유출 시도
- DevOps 에이전트에 파괴적 변경을 유도하는 명령 삽입
- 에이전트에게 감사 로그 축소나 비활성화를 요구하는 프롬프트 투입
이때 확인해야 할 것은 단순한 차단 여부만이 아닙니다. 어떤 에이전트 계정 권한이 사용되었는지, 어떤 정책이 개입했는지, 어떤 감사 로그가 남았는지까지 함께 봐야 레드팀 연계 구조가 실질적인 방어 체계가 됩니다.
9. 실전 블루프린트와 체크리스트
가상의 중견 기업이 문서 요약 에이전트와 DevOps 에이전트를 웹 포털과 Slack에 연결한다고 가정해 보겠습니다. 이때 AI 에이전트 보안 아키텍처는 각 에이전트의 AI 공격 표면을 먼저 표로 정리하는 것에서 시작합니다.
| 에이전트 | 채널 | 접근 대상 | 기본 권한 |
|---|---|---|---|
| 문서 요약 | 웹, Slack | Confluence, SharePoint | ReadOnly + 요약 |
| DevOps | 웹, Slack | GitHub, CI/CD, 클라우드 메타데이터 | DescribeOnly, PR 생성 |
그 다음 각 에이전트에 별도 서비스 계정을 만들고, Gateway-오케스트레이터-툴 게이트웨이-SIEM 구조로 배치합니다. 필수 이벤트는 세션 시작과 종료, 툴 호출, 정책 차단, 승인 여부, 오류입니다. 특히 기밀 문서 전체 출력과 main 브랜치 직접 변경은 SIEM 룰로 탐지되도록 설계해야 합니다.
최종 체크리스트
- 서비스 계정 분리
- 툴 최소 권한
- 감사 로그 필수 필드 확보
- 세션 리플레이 가능성 확보
- 정기 레드팀 플레이북 운영
- SIEM 연계 및 탐지 룰 정의
이 여섯 가지가 빠지면 아키텍처는 있어도 운영 가능한 방어 체계라고 보기 어렵습니다. 결국 블루프린트의 목적은 예쁜 다이어그램이 아니라, 실제 침해 상황에서 추적과 차단이 가능한 구조를 만드는 데 있습니다.
10. 운영·거버넌스와 결론
기술만으로는 운영되지 않습니다. 보안 아키텍트는 표준을 세우고, 클라우드 보안 담당자는 IAM과 네트워크 정책을 구현하며, 플랫폼 엔지니어는 오케스트레이터와 로깅 파이프라인을 운영해야 합니다. 레드팀과 블루팀은 검증과 대응을 맡아야 하고, 조직 차원에서는 책임 분리가 명확해야 합니다. 국내에서도 정책·거버넌스 논의가 AI 활용 기준과 책임 구조를 함께 가져가야 한다고 설명합니다.
마지막으로, 바로 적용할 점검 항목은 아래와 같습니다.
- 에이전트별 서비스 계정이 사람 계정과 분리되어 있는가?
- 최소 권한과 세션 기반 임시 권한이 적용되어 있는가?
- 툴 권한이 리소스·행위 단위로 세분화되어 있는가?
- 에이전트별 AI 공격 표면 인벤토리가 문서화되어 있는가?
- 감사 로그에 주체·세션·툴 호출·정책 결정이 남는가?
- 프롬프트와 세션 로그에 마스킹·보존 정책이 있는가?
- 정기적인 레드팀 테스트와 레드팀 연계 구조가 있는가?
- 프롬프트 가드레일과 런타임 정책 엔진이 함께 있는가?
- SIEM과 연계된 탐지 룰이 정의되어 있는가?
- 조직의 역할과 책임이 명확한가?
정리하면, 기존 AI 보안 아키텍처 위에 에이전트 계정 권한, 정책·가드레일, 감사 로그, 레드팀 연계 구조를 얹어야 비로소 완성된 AI 에이전트 보안 아키텍처가 됩니다. 앞으로 멀티에이전트 환경이 늘어날수록 권한 위임, 에이전트 간 통신, 규제 매핑의 중요성은 더 커질 것입니다. 지금 필요한 첫걸음은 복잡한 기술이 아니라, 우리 에이전트는 어디에 닿고 무엇을 할 수 있으며 그 행동이 어떻게 보이는가를 설계 문서로 남기는 일입니다.
자주 묻는 질문 (FAQ)
AI 보안 아키텍처와 AI 에이전트 보안 아키텍처는 무엇이 다른가요?
AI 보안 아키텍처가 모델, 데이터, 인프라, MLOps 보호에 초점을 둔다면, AI 에이전트 보안 아키텍처는 여기에 세션, 메모리, 툴 실행, 계정 권한, 감사 로그, 레드팀 운영까지 포함합니다. 즉 에이전트의 실제 행동과 연결 권한을 중심으로 설계 범위가 넓어집니다.
에이전트 계정 권한은 왜 사람 계정과 분리해야 하나요?
사람 계정을 재사용하면 추적이 어렵고 권한이 과도하게 넓어질 수 있습니다. 에이전트 전용 계정으로 분리해야 최소 권한을 적용하고, 세션 단위로 권한을 통제하며, 사고 발생 시 어떤 에이전트가 어떤 행동을 했는지 명확하게 확인할 수 있습니다.
감사 로그에는 어떤 정보가 꼭 남아야 하나요?
최소한 에이전트 ID, 최종 사용자 ID, 세션 ID, Correlation ID, 모델 이름과 버전, 프롬프트 요약, 툴 이름, 마스킹된 파라미터, 실행 결과, 정책 엔진 판단 결과는 남아야 합니다. 그래야 사고 조사와 정책 개선이 가능합니다.
레드팀 연계 구조는 꼭 필요한가요?
필수에 가깝습니다. 에이전트 보안은 설계만으로 완성되지 않고, 실제 공격 시나리오로 검증해야 약점을 찾을 수 있습니다. 레드팀 결과가 IAM, 정책, 로그, SIEM 룰 개선으로 이어져야 운영 가능한 보안 체계가 됩니다.
출처 및 참고자료
- Obsidian Security – Security for AI Agents
- AWS – OWASP GenAI 보안 평가 가이드
- CrowdStrike – AI Agent Security Architecture, Attack Surface, Defense
- arXiv – Agentic AI Security Research
- AIMultiple – Agentic AI Cybersecurity
- Microsoft Tech Community – Securing AI Agents
- Okta – Understanding the AI Agent Identity Challenge
- SentinelOne – SIEM Architecture
- Microsoft Learn – AI Red Teaming Agent
- CSA – NIST AI Agent Red Teaming Standards
- CELA – 정책·거버넌스 논의