기업 내부데이터 연동형 AI 보안은 더 이상 대기업만의 과제가 아닙니다. 사내 문서 검색, 고객센터 챗봇, 헬프데스크 자동화가 늘어나면서 내부 데이터와 생성형 AI를 연결하는 순간부터 개인정보, 영업비밀, 권한 오남용, 로그 잔존 문제가 동시에 발생할 수 있습니다.
이 글은 AI 챗봇 개인정보 보호 가이드를 실제 정책 초안 수준으로 설계할 수 있도록 데이터 흐름, 규제 원칙, 기술 통제, 역할별 체크리스트, 도입 로드맵까지 한 번에 정리한 실무형 안내서입니다.
목차
- 이 글을 읽는 방법: 역할별 로드맵
- 1. 왜 지금 기업 내부데이터 연동형 AI 보안인가
- 2. 생성형 AI·챗봇과 내부데이터 연동 구조 이해
- 3. 현장에서 자주 터지는 위험 시나리오
- 4. 기업 내부데이터 연동형 AI 보안에 필요한 규제 원칙
- 5. 아키텍처·기술 설계와 AI 챗봇 개인정보 보호 가이드
- 6. AI 챗봇 개인정보 보호 가이드: 정책 문장 초안
- 7. 기업 내부데이터 연동형 AI 보안 체크리스트
- 8. 중소기업 단계별 도입 로드맵
- 자주 묻는 질문
- 출처 및 참고자료
이 글을 읽는 방법: 역할별 로드맵
이 글은 기업 내부데이터 연동형 AI 보안을 이해하고, 사내에서 바로 쓸 수 있는 AI 챗봇 개인정보 보호 가이드를 설계하려는 분들을 위한 실무 로드맵입니다. 규제, 보안, 기술, 운영 관점을 한 번에 묶어 실행 가능한 형태로 정리했습니다.
| 역할 | 먼저 읽을 섹션 |
|---|---|
| 법무·개인정보 | 4, 6-2~6-5, FAQ |
| 보안·IT | 1, 2, 5, 7 |
| 개발·데이터팀 | 2, 5, 6-3, 7 |
| 운영·현업 | 도입부, 3, 6-2, 7, 8 |
1. 왜 지금 기업 내부데이터 연동형 AI 보안인가
사내 지식 검색과 업무 자동화에 생성형 AI를 붙이는 흐름은 이미 넓게 퍼졌습니다. 내부 문서를 연결한 AI 도입 논의가 늘고 있고, 보안 업계도 실제 업무 환경에서의 활용 확산을 짚고 있습니다. 관련 흐름은 Alyac과 보안뉴스 자료에서도 확인할 수 있습니다. 이제는 대기업뿐 아니라 중소기업도 기업 내부데이터 연동형 AI 보안을 본격적으로 고민해야 하는 단계입니다.
문제는 파일럿이 너무 쉽게 시작된다는 점입니다. 직원이 고객정보나 계약 초안을 외부 LLM API에 붙여 넣는 순간, 데이터는 요청 본문, 응답, 애플리케이션 로그, 클라우드 처리 과정 어딘가에 남을 수 있습니다. 이런 위험은 Exosp가 설명하듯 개인정보 목적 외 이용, 국외 이전, 영업비밀 노출로 이어질 수 있습니다.
막는 것보다 중요한 일은 어디로 흐르고, 무엇이 남고, 누가 보는지를 설계하는 것입니다.
보안팀은 막고 싶고, 현업은 빨리 쓰고 싶어 합니다. 이 갈등을 푸는 현실적인 방법은 금지가 아니라 구조 이해, 규제 정리, 통제 설계입니다. 그래서 AI 챗봇 개인정보 보호 가이드는 단순 기술 문서가 아니라 경영과 운영을 함께 묶는 정책 문서가 되어야 합니다.

2. 생성형 AI·챗봇과 내부데이터 연동 구조 이해
2-1. 데이터 흐름과 아키텍처
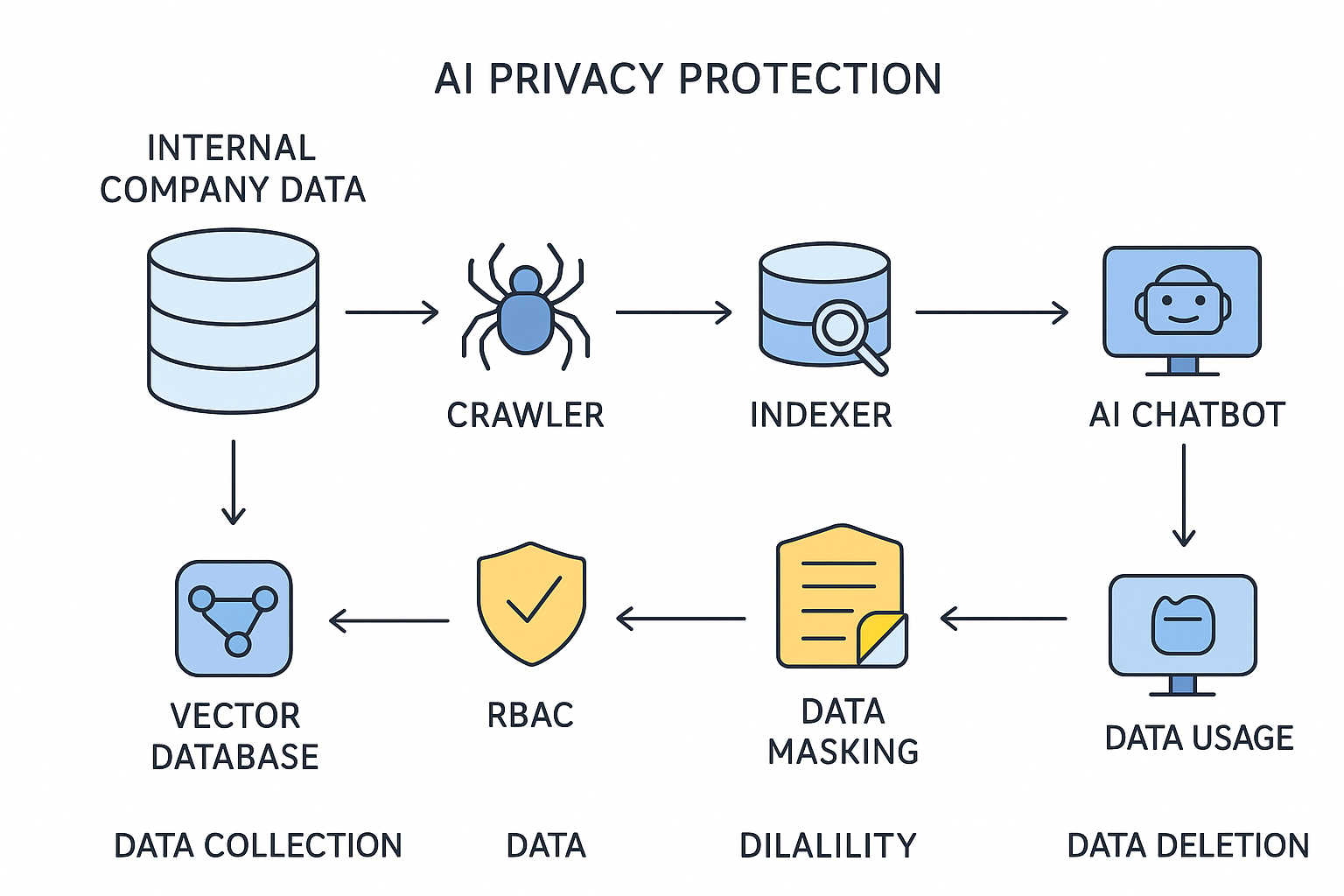
전형적인 구조는 단순합니다. 내부 저장소에 있는 문서를 크롤러가 읽고, 인덱서가 검색용 색인을 만들며, 벡터DB가 문서 의미를 임베딩 형태로 저장합니다. 이후 챗봇은 사용자 질문을 받아 관련 문서를 검색하고, RAG 방식으로 LLM에 넘겨 답을 만듭니다. Google Cloud도 생성형 AI 보안 설계에서 이런 데이터 흐름 가시화를 먼저 권장합니다.
핵심은 어디에 남는가입니다. 인덱싱 단계에서는 원문 일부가 임베딩이나 캐시에 남을 수 있고, LLM 호출 단계에서는 요청과 응답이 처리 로그에 기록될 수 있습니다. 또 챗봇 애플리케이션 DB에는 세션 정보와 대화 기록이, 모니터링 시스템에는 복제 로그가 쌓입니다. 따라서 기업 내부데이터 연동형 AI 보안 요구사항은 기능보다 먼저 데이터 흐름도에서 출발해야 합니다.
2-2. 데이터 생애주기로 보는 개인정보 보호
개인정보 관점에서는 흐름을 수집–저장–분석·학습–제공–파기로 보면 이해가 쉽습니다. 이 구조는 개인정보위 안내서의 기본 원칙과도 맞닿아 있습니다. 사용자가 챗봇에 질문과 파일을 넣는 순간 수집이 시작되고, 로그와 인덱스에 기록되면 저장이 됩니다. LLM이 응답을 만드는 과정은 분석·추론 단계이며, 이 로그를 나중에 모델 개선에 다시 쓰면 목적 외 이용 문제가 생길 수 있습니다.
마지막으로 응답이 사용자에게 전달될 때 다른 사람의 정보가 섞여 나올 위험이 있고, 삭제 시에는 로그·백업·인덱스까지 함께 지워야 비로소 실질적 파기가 됩니다. 이 생애주기는 이후 설계할 정책의 뼈대가 됩니다.
2-3. 기존 보안 원칙 위에 AI 통제 더하기
기업 데이터 보안의 기본은 기밀성, 무결성, 가용성입니다. 여기에 문서 등급 분류와 저장·전송·사용 중 보호가 붙습니다. SentinelOne이 설명하듯 생성형 AI를 도입한다고 완전히 새로운 보안 체계가 필요한 것은 아닙니다. 기존 엔터프라이즈 보안 위에 AI 특화 통제를 덧붙이는 작업에 가깝습니다.
3. 현장에서 자주 터지는 위험 시나리오
| 시나리오 | 실제 문제 | 필요한 통제 |
|---|---|---|
| 상담사가 고객정보를 통째로 입력 | 개인정보 외부 전송, 로그 잔존 | 민감정보 입력 금지, 교육 |
| 전략 회의록·계약 초안 입력 | 영업기밀 유출 | 승인 절차, 문서 등급 통제 |
| 프롬프트 인젝션 | 숨은 지시로 데이터 추출 | 프롬프트 필터, 출력 필터 |
| 잘못된 폴더 권한 상태에서 AI 검색 도입 | 권한 오남용이 대량 노출로 확대 | RBAC/ABAC, 권한 재점검 |
| 로그 정책 부재 | 삭제 요청 대응 실패 | 보관·삭제 정책, 감사로그 |
상담사가 고객 이름, 전화번호, 주소, 주문내역을 한 번에 붙여 넣는 장면은 매우 현실적입니다. 이런 경우 고객은 자신의 정보가 어디까지 갔는지 물을 수 있지만, 회사는 답하기 어려워집니다. 실무 현장 사례는 트랜스코스모스 자료에서도 확인할 수 있습니다.
- 정책: 민감정보 입력 금지 목록 수립
- 교육: 직원용 생성형 AI 사용 수칙 배포
- 기술: 입력 필터와 마스킹 적용
또 다른 위험은 문서나 입력창에 숨은 지시를 심어 챗봇을 속이는 공격입니다. 비젠소프트가 설명하듯, 이런 공격은 검색 계층 권한 필터와 컨텍스트 분리가 없을 때 더 커집니다.
권한 문제도 자주 간과됩니다. Microsoft 365 Copilot류 도구는 기존 권한을 존중하지만, 원래 권한이 잘못되어 있으면 AI가 그 문제를 더 빨리 드러냅니다. 이 점은 Cloocus가 정리한 보안 인사이트에서도 확인됩니다.
4. 기업 내부데이터 연동형 AI 보안에 필요한 규제 원칙
국내 가이드의 핵심은 네 가지입니다. 필요한 범위만 최소 수집하고, 목적을 분명히 하며, 보관 기간을 줄이고, 가명·익명처리와 국외 이전 절차를 챙기는 것입니다. 이는 KISA가 제시하는 기본 원칙과도 일치합니다.
직원 교육에는 이용자용 보호 가이드도 유용합니다. 중요한 개인정보를 AI 서비스에 넣지 말고, 처리방침과 국외 이전 여부를 확인하며, 삭제·정정 권리 행사 방법을 알아두라는 내용은 그대로 사내 사용 수칙으로 바꿀 수 있습니다. 관련 실무형 설명은 개인정보위 블로그에서 확인할 수 있습니다.
해외 고객이나 해외 법인을 상대한다면 GDPR 원칙도 함께 봐야 합니다. 합법성·투명성, 목적 제한, 데이터 최소화, 보관 제한, 무결성·기밀성, 책임성은 AI에도 그대로 적용됩니다. 원칙 설명은 GDPR 원문 설명에서 확인할 수 있습니다.

5. 아키텍처·기술 설계와 AI 챗봇 개인정보 보호 가이드
5-1. LLM 환경 선택
| 방식 | 장점 | 주의점 |
|---|---|---|
| SaaS형 LLM API | 빠른 도입, 운영 부담 적음 | 국외 이전, 로그 정책, 계약 검토 |
| 클라우드 관리형 | IAM·VPC·키 관리 연계 | 클라우드 설계 역량 필요 |
| 온프레미스/프라이빗 | 데이터 통제력 높음 | 운영·패치·튜닝 부담 큼 |
OpenAI Enterprise Privacy는 비즈니스 환경에서 업로드 데이터가 기본적으로 모델 학습에 사용되지 않도록 하는 옵션과 프라이버시 통제를 안내하고 있습니다. 다만 이것이 곧 아무 데이터나 넣어도 된다는 뜻은 아닙니다. 계약 조건, 저장 옵션, 관리자 설정을 함께 봐야 합니다.
5-2. 데이터 분리와 네트워크 격리
사내망 또는 전용 VPC 안에서 접근을 제한하고, 벡터DB와 원문 저장소를 분리해야 합니다. Google Cloud는 생성형 AI 보안 모범사례에서 네트워크 분리, 최소 권한, 데이터 경계 설정을 강조합니다.
민감 필드는 앱 계층에서 마스킹하거나 토큰화한 뒤 LLM에 넘기는 방식이 실무적으로 유용합니다. 즉, LLM은 꼭 필요한 문서 조각만 보고 원문 전체는 보지 않게 만드는 구조가 더 안전합니다.
5-3. 권한 기반 검색
검색 단계에서 사용자 ID, 부서, 역할 정보를 함께 보내고 RBAC·ABAC 필터를 거쳐야 합니다. 그래야 사용자가 원래 볼 수 있는 문서만 응답에 쓰입니다. Copilot 사례가 보여주듯, AI 이전에 권한 정리가 먼저입니다. 자세한 실무 포인트는 Cloocus 자료가 참고됩니다.
5-4. 로깅·감사·모니터링
누가, 언제, 어떤 문서에 접근했고 어떤 질문과 응답이 오갔는지 남겨야 합니다. 다만 로그에는 직접 식별자보다 내부 ID를 쓰고, 대화 전문 장기 보관보다 메타데이터 중심 요약이 더 바람직합니다. 이상한 대량 질의나 고위험 문서 반복 조회는 탐지 룰로 관리해야 하며, 운영 관점의 보안 포인트는 Dfinite 자료가 도움이 됩니다.
6. AI 챗봇 개인정보 보호 가이드: 정책 문장 초안
- 사전평가: ‘당사는 신규 AI 챗봇 도입 시 개인정보 영향평가(DPIA)와 위험 분석을 수행한다.’ 관련 실무 가이드는 Google Cloud Blog에서 참고할 수 있습니다.
- 수집 최소화: ‘임직원은 생성형 AI·챗봇에 주민등록번호, 금융정보, 건강정보, 형사정보 등 고위험 민감정보를 입력할 수 없다.’ 기준선은 KISA 자료를 참조할 수 있습니다.
- 가명처리: 이름은 임의 ID로 바꾸고 전화번호·주민번호는 부분 마스킹합니다. 다만 가명정보도 규제 대상이며 결합 시 재식별될 수 있다는 점을 네이버 프라이버시 설명에서 확인할 수 있습니다.
- 보관·삭제: ‘외부 LLM 전송 데이터는 가능한 경우 단기 보관 또는 비보관 옵션을 우선 사용하고, 불가피한 보관은 계약서에 조건을 명시한다.’ 정책 검토 시 OpenAI Privacy Policy 같은 제공자 문서를 함께 읽어야 합니다.
- 국외이전 관리: 개인정보가 해외 리전 LLM으로 가는 경우 고지·동의·계약 절차를 점검해야 하며, 세부 기준은 개인정보위 안내서를 확인해야 합니다.
정책 문장은 짧고 분명해야 합니다. 특히 금지 입력 항목, 승인 절차, 보관 기한, 예외 승인 주체를 명시해야 실제 운영에서 흔들리지 않습니다. 보다 실행 중심으로 점검하려면 기업 내부데이터 연동형 AI 보안 체크리스트 형태로 역할별 책임을 분리하는 것이 효과적입니다.
7. 기업 내부데이터 연동형 AI 보안 체크리스트
| 역할 | 핵심 점검 |
|---|---|
| 보안 | VPC 격리, MFA, 암호화, KMS, SIEM 연동, 이상행위 탐지, NIST AI RMF 참조 |
| 법무·개인정보 | 처리방침 목적 반영, 위탁·제3자 제공 조항, DPIA, 계약 조항 점검, 법률 자료 참고 |
| 개발·데이터 | 프롬프트 Privacy Filter, 권한 필터링, 출력 차단, 배포 전 테스트, 개발 참고 |
| 운영·현업 | 금지 정보 교육, 고위험 답변 2인 검토, 가이드 서약, 직원용 수칙 배포, 개인정보위 블로그 참고 |
이 체크리스트의 목적은 복잡한 원칙을 역할별 행동으로 바꾸는 데 있습니다. 기업 내부데이터 연동형 AI 보안은 한 부서가 단독으로 지킬 수 없고, 책임 분담이 선명해야 실제로 작동합니다.
8. 중소기업 단계별 도입 로드맵
먼저 현재 사용 중인 공개형 챗봇과 AI 도구를 조사해야 합니다. 어떤 부서가 어떤 데이터를 넣는지부터 알아야 위험이 보입니다. 이 초기 진단의 중요성은 트랜스코스모스 사례에서도 확인됩니다.
다음으로 AI 챗봇 개인정보 보호 가이드 초안을 만들고, 승인된 도구와 금지 정보를 정리해 교육합니다. 실무 참고용으로는 생성형 AI 활용 보안 가이드라인 PDF가 도움이 됩니다.
파일럿은 공지, 규정집, FAQ, 제품 매뉴얼처럼 저위험 데이터부터 시작하는 것이 좋습니다. 이후 고객정보나 계약정보 같은 고위험 영역은 DPIA와 계약 검토를 마친 뒤 확대해야 합니다. Samsung SDS도 생성형 AI 보안에서 단계적 통제와 운영 체계를 강조합니다.
마지막으로 정기 점검과 룰 개선을 반복해야 합니다. 운영 과정의 지속적 점검 필요성은 Dfinite 자료가 잘 정리하고 있습니다.
실행 순서 요약
- 사내 AI 사용 현황 조사
- 데이터 흐름도 작성
- 승인 도구와 금지 입력 항목 정의
- 저위험 데이터로 파일럿 시작
- 고위험 영역은 사전평가 후 확대
- 정기 감사와 정책 업데이트 반복
결론: 보안을 설계해서 AI를 안전하게 쓰는 것
기업 내부데이터 연동형 AI 보안은 첨단 기술 자체보다, 기존 보안과 개인정보 원칙을 AI 맥락에 맞게 다시 설계하는 일에 가깝습니다. 핵심은 네 가지입니다.
- 데이터 최소화와 비식별화
- 권한 기반 검색과 권한 재점검
- 명확한 보관·삭제 정책
- 역할별 책임 분담
지금 바로 할 일도 분명합니다. 먼저 회사가 쓰는 AI 도구를 목록으로 정리하고, 고객정보·계약문서·소스코드가 어디서 AI로 흘러가는지 데이터 흐름도를 그려야 합니다. 그다음 이 글의 정책 문장 초안을 바탕으로 2~3페이지짜리 사내 가이드를 만드세요. AI를 막는 조직보다, 안전하게 설계한 조직이 더 오래 앞서갑니다.
자주 묻는 질문 (FAQ)
대화 로그를 학습데이터로 써도 되나요?
가능하더라도 제한적이어야 합니다. 목적, 보관 기간, 동의 범위가 분명해야 하고, 가명처리와 최소화를 전제로 해야 합니다. 실무 기준은 가이드라인 PDF를 참고할 수 있습니다.
고객이 삭제를 요청하면 AI 쪽에서도 지워야 하나요?
원칙적으로 로그, 인덱스, 학습데이터에서 가능한 범위의 삭제·비활성화 절차를 마련해야 합니다. 기술적으로 어려운 부분이 있으면 그 사실도 투명하게 알려야 합니다. 관련 원칙은 GDPR 설명에서도 확인할 수 있습니다.
온프레미스 오픈소스 LLM이면 규제에서 자유로운가요?
아닙니다. 외부 전송 위험은 줄어도 수집, 저장, 접근권한, 파기 의무는 여전히 기업 책임입니다. 이 점 역시 가이드라인 PDF가 분명히 보여줍니다.
해외 클라우드 LLM은 국외 이전인가요?
개인정보가 해외 서버로 전송·저장된다면 국외 이전에 해당할 가능성이 큽니다. 제공자의 데이터 위치 문서를 확인하고 법무 검토를 거쳐야 합니다. 세부 기준은 개인정보위 안내서를 참고하세요.
출처 및 참고자료
- Alyac
- 보안뉴스
- Exosp – AI Security
- Google Cloud – Generative AI Security Best Practices
- 개인정보위 안내서
- SentinelOne – Enterprise Data Security
- 트랜스코스모스
- 비젠소프트
- Cloocus – Copilot Security Insights
- KISA
- 개인정보위 블로그
- GDPR 원문 설명
- OpenAI Enterprise Privacy
- Dfinite
- Google Cloud Blog – DPIA and AI Privacy Compliance
- 네이버 프라이버시
- OpenAI Privacy Policy
- NIST AI Risk Management Framework
- 법률 자료 PDF
- 개발 참고
- 생성형 AI 활용 보안 가이드라인 PDF
- Samsung SDS