Claude Opus 4.7 코딩 성능은 단순 자동완성보다 코드 읽기, 문맥 이해, 리뷰, 리팩토링, 디버깅 같은 실무형 작업에서 가치가 있는지로 판단해야 합니다. 특히 여러 파일과 긴 대화 맥락을 유지하면서 설계 원칙까지 따라가는지가 핵심입니다.
이 글은 공개 벤치마크, 외부 리뷰, 워크플로우 시나리오를 기준으로 Claude Opus 4.7 코드 리팩토링 에이전트로 실무에 투입할 만한지 따져봅니다. 또한 Claude Opus 4.7 개발자 후기를 함께 살펴보며, 실제 도입 시 기대할 수 있는 이득과 한계를 정리합니다.
핵심 요약
Claude Opus 4.7 코딩 성능은 짧은 코드 생성보다 멀티파일 이해, PR 리뷰, 로그 분석, 레거시 개선처럼 긴 문맥을 다루는 업무에서 더 강하게 체감됩니다. 다만 자동 적용보다는 자동 제안 + 사람 승인 구조로 운영해야 안정적이며, 보안 정책과 팀 규칙이 정리된 조직에서 특히 효과가 큽니다.
목차
- 1. Claude Opus 4.7 개요: 코딩·에이전트 업데이트 핵심
- 2. Claude Opus 4.7 코딩 성능: 시나리오별 평가
- 3. Claude Opus 4.7 코드 리팩토링 에이전트로 쓰기
- 4. 워크플로우별 활용 패턴
- 5. Claude Opus 4.7 개발자 후기 정리
- 6. 기존 모델·도구와 비교: 언제 이득인가
- 7. 실전 도입 가이드
- 8. 장단점 총정리와 추천 시나리오
- 자주 묻는 질문

1. Claude Opus 4.7 개요: 코딩·에이전트 업데이트 핵심
Claude Opus 4.7 코딩 성능을 제대로 보려면 먼저 이 모델이 어디에 초점을 둔 업데이트인지 이해해야 합니다. Opus 라인은 Anthropic의 상위 라인업으로 인식되며, 이번 4.7은 코딩, 도구 호출, 장시간 에이전트 세션에 더 맞춰진 버전으로 소개됩니다.
출시 특징과 포지셔닝은 Risemoment 정리, 비교 가이드, NXCode 분석에서 공통적으로 확인할 수 있습니다.
중요한 차이는 코드를 한 번에 잘 쓰느냐보다, 긴 세션 안에서 팀 규칙과 앞선 합의를 얼마나 유지하느냐입니다.
실무에서는 티켓 설명, 서비스 코드, 테스트, 로그를 함께 넣고 원인 분석과 수정 방향을 묻는 일이 많습니다. 이때 모델이 여러 조각을 연결해 설명하고, 수정 순서를 제안하며, 후속 검증까지 이어갈 수 있다면 그때부터는 단순 챗봇이 아니라 개발 파트너에 가까워집니다.
코딩 성능을 볼 때 체크할 평가 축
| 평가 축 | 보는 포인트 |
|---|---|
| 이해 능력 | 기존 코드, 티켓, 설계 문서를 읽고 문제를 정확히 설명하는가 |
| 생성 능력 | 새 코드와 테스트를 팀 스타일에 맞게 만드는가 |
| 리팩토링·리뷰 | 구조 개선, 성능·보안 이슈 탐지, 컨벤션 정렬이 되는가 |
| 워크플로우 적합성 | PR, CI/CD, 티켓 기반 프로세스에 자연스럽게 들어가는가 |
이 기준으로 보면 Claude Opus 4.7 코딩 성능은 짧은 스니펫 생성보다 멀티파일 이해와 장기 세션 유지에서 차별화됩니다.
2. Claude Opus 4.7 코딩 성능: 시나리오별 평가
기능 개발 보조
티켓 설명과 기존 서비스 코드 일부를 함께 주고 API 엔드포인트, 핸들러, 서비스 레이어 구현을 맡기면 폴더 구조와 레이어 패턴을 먼저 읽고 비슷한 방식으로 맞추려는 성향이 강합니다. 기존 네이밍, 예외 처리, 로깅 패턴을 따라가려는 점도 실제로 유용합니다.
정량 지표도 나쁘지 않습니다. 외부 자료에 따르면 이전 버전 대비 코딩 벤치마크에서 11~15% 개선되었다고 소개되며, 다른 비교 자료에서는 SWE-bench Pro 64.3%, CursorBench 70% 수준으로 정리됩니다. 같은 수치는 NXCode 가이드에서도 확인됩니다.
- 초안 작성 속도는 빠르지만, 최신 프레임워크의 세부 API는 놓칠 수 있습니다.
- 프로젝트 전용 유틸 규칙은 자동으로 완벽히 따르지 못할 수 있습니다.
- 반복 제약 조건을 상단 프롬프트에 명시할수록 결과가 안정됩니다.
디버깅과 로그 분석
버그 분석에서는 스택 트레이스, 관련 코드, 재현 절차를 함께 줄 때 강점이 분명해집니다. 특히 원인 후보 → 가장 가능성 높은 원인 → 패치 초안 → 검증 테스트 순서로 요청하면 결과가 더 구조적입니다.
이 부분은 Risemoment 리뷰와 업그레이드 가이드에서도 장점으로 언급됩니다. 또한 Techsuda 정리 역시 코딩·추론 강화 흐름을 긍정적으로 평가합니다.
다만 환경 의존 버그는 별개입니다. OS 설정, DB 격리 수준, 컨테이너 네트워크처럼 런타임 변수가 큰 문제는 추측성 답변이 나올 수 있으므로, 긴 로그 전체보다 에러 전후 핵심 구간만 정제해서 주는 편이 더 좋습니다.
성능 이슈 분석
N+1 쿼리, 대량 로딩, 비효율 루프, 동시성 병목 같은 문제는 단순 자동완성 도구보다 긴 맥락 이해형 모델에서 더 차이가 납니다. 저는 보통 병목 후보를 먼저 뽑고, 각 후보의 근거와 trade-off를 설명하라고 요청합니다.
요약하면, Claude Opus 4.7 코딩 성능은 손보다 머리를 더 많이 쓰는 작업에서 진가가 드러납니다.
3. Claude Opus 4.7 코드 리팩토링 에이전트로 쓰기
에이전트처럼 쓴다는 뜻
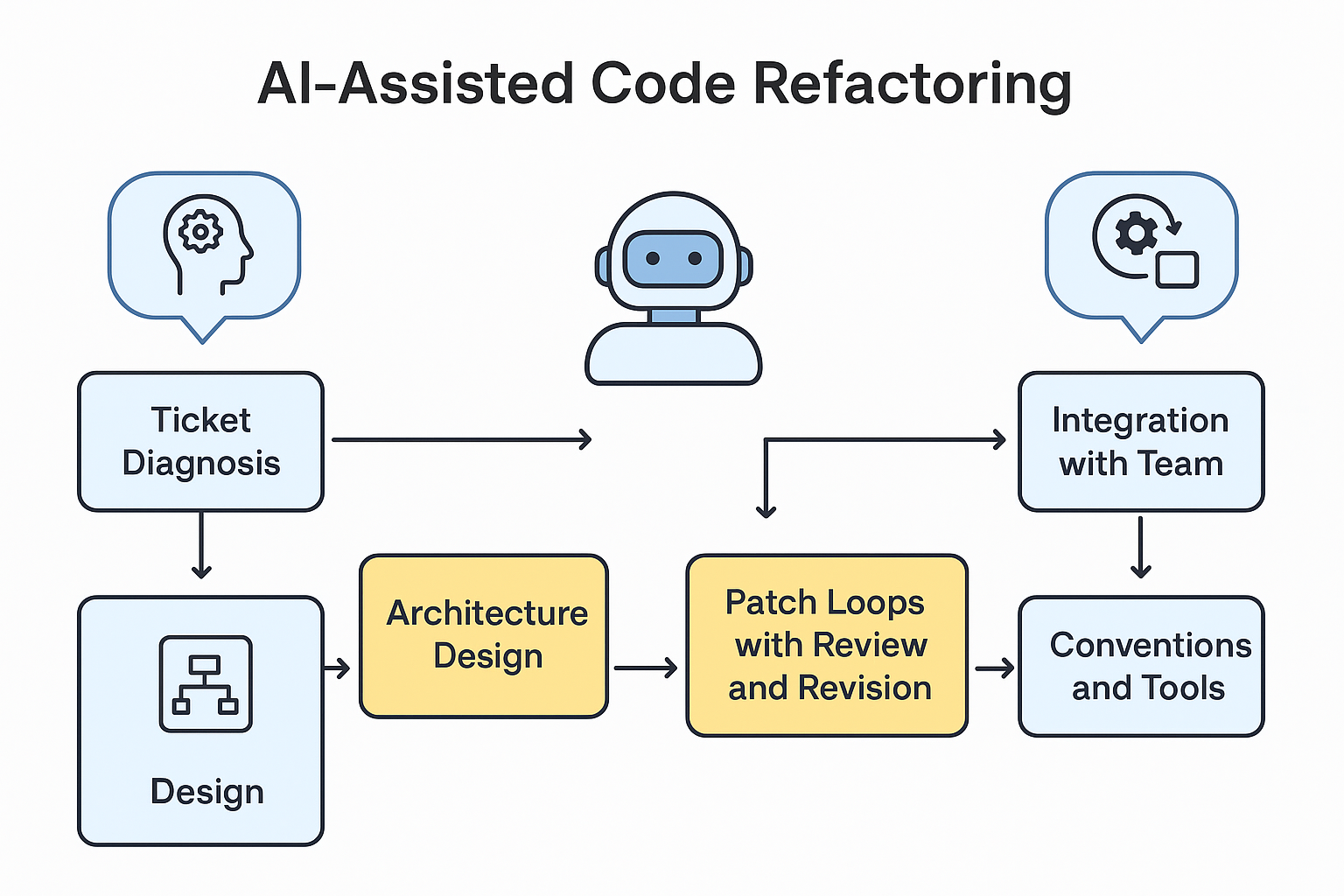
Claude Opus 4.7 코드 리팩토링 에이전트는 한 번 묻고 끝나는 도구가 아닙니다. 동일한 코드베이스와 브랜치를 기준으로 리팩토링 티켓 처리, PR 리뷰, 수정, 재검토까지 이어지는 루프를 맡기는 방식입니다.
이 접근이 가능한 이유는 4.7이 tool use와 장시간 세션에 맞춰졌고, 코딩 개선과 에이전트형 활용이 강조되기 때문입니다. 여기서는 단일 응답 품질보다 연속 작업의 일관성이 더 중요합니다.
레거시 모듈 구조 개선 시나리오
| 단계 | 입력/요청 | 기대 결과 |
|---|---|---|
| 1. 진단 | 주요 파일, 장애 포인트, 불만 사항 제공 | 결합도, 응집도, 순환 의존, 거대 클래스 식별 |
| 2. 목표 설계 | 원하는 아키텍처 원칙 제시 | 타깃 구조와 분리 전략 제안 |
| 3. 실행 계획 | 단계별 변경 범위 요청 | 리스크, 테스트 목록, 순서가 있는 계획표 |
| 4. 패치 루프 | 단계별 코드 수정 요청 | diff 초안, 테스트 보강, 후속 수정안 |
이 방식의 장점은 상위 설계와 실제 코드 변경이 하나의 세션에서 이어진다는 점입니다. 그래서 레거시 개선을 한 번에 갈아엎는 작업이 아니라 작게 쪼개서 검증하며 바꾸는 작업으로 바꿔 줍니다.
팀 컨벤션과 도구 연동
예를 들어 Controller는 Repository 직접 접근 금지, public API는 공통 로깅 필수 같은 제약을 미리 주면 그 틀 안에서 바꾸도록 유도할 수 있습니다. 네이밍 통일, dead code 제거, 레이어 침범 탐지 같은 반복 작업도 잘 맞습니다.
IDE, CLI, GitHub 앱과 연결해 수정 → 테스트 → 실패 로그 분석 → 재수정 루프를 만들면 에이전트형 활용 가치가 더 커집니다. 다만 운영 원칙은 분명합니다. 자동 적용보다 자동 제안 + 사람 승인 구조가 안전합니다.
4. 워크플로우별 활용 패턴
티켓 드리븐 개발
Claude Opus 4.7 코딩 성능은 Jira나 Linear 같은 티켓 기반 개발에서 특히 잘 드러납니다. 티켓, 핵심 코드 파일, 최근 로그를 함께 주고 아래 형식으로 정리하게 하면 초안 품질이 높아집니다.
- 문제 요약
- 영향 범위
- 해결 전략
- 실제 작업 체크리스트
- 패치 초안
- 테스트 초안
이 패턴은 Risemoment 자료에서 소개된 코딩 활용 흐름과도 맞습니다. 개발자는 빈 화면에서 시작하는 대신 구조화된 초안을 검토하고 다듬는 역할로 이동합니다.
코드 리뷰 자동화
PR diff를 넣고 기능 요약, 리스크, 설계 이슈, 스타일 문제를 구분해 보게 하면 리뷰 품질이 올라갑니다. 단순 린트성 코멘트보다 의존성 방향, 책임 분리, 레이어 침범 같은 설계 수준 피드백이 더 가치 있습니다.
이런 깊이 있는 리뷰는 NXCode 분석에서 강조된 장점과도 맞닿아 있습니다. 리팩토링 PR에서는 먼저 구조 문제를 요약하게 하고, 그다음 수정 우선순위를 제안하게 하면 팀 리드의 부담이 크게 줄어듭니다.
테스트·문서 자동 생성
기존 코드와 시나리오 설명을 주고 테스트 스켈레톤을 생성하게 하는 방식도 실용적입니다. 다만 Jest, Vitest, JUnit, TestNG처럼 테스트 프레임워크를 반드시 명시해야 합니다. 이 사용 팁은 업그레이드 가이드 관점에서도 중요합니다.
실제로는 테스트 초안과 API 문서 초안을 모델이 만들고, 개발자는 assertion, edge case, mock 데이터 조정에 집중하는 분업이 가장 현실적입니다.
5. Claude Opus 4.7 개발자 후기 정리
외부 평가와 체감 포인트
Claude Opus 4.7 개발자 후기를 종합하면 방향은 꽤 분명합니다. 여러 자료는 4.7이 코딩 벤치마크 개선, 멀티파일 이해, 장시간 세션 안정성에서 강하다고 봅니다. 특히 Risemoment, Techsuda, NXCode는 공통적으로 실제 복잡한 코딩 워크로드에 더 잘 맞는다고 평가합니다.
- 코드 리뷰 시간 단축: 1차 기계 리뷰 후 2차 사람 리뷰 구조가 쉬워집니다.
- 레거시 공포 감소: 구조 요약과 리팩토링 계획을 빠르게 받을 수 있습니다.
- 장애 대응 속도 개선: 로그와 코드 조각으로 원인 후보를 빠르게 좁힐 수 있습니다.
여기서 중요한 점은 체감 가치가 코드 한 줄 더 빨리 쓰기보다 무엇을 먼저 봐야 하는지 빨리 정리해 주는 능력에서 나온다는 것입니다.
부정적·중립적 후기
물론 단점도 반복됩니다. 메이저 언어에 비해 특수 스택 편차가 있고, 긴 세션에서 초반 합의를 놓치는 경우가 있으며, 외부 LLM 사용이 어려운 조직에서는 보안 제약이 큽니다.
그래서 세션 중간마다 현재까지 합의사항 요약을 다시 요청하는 습관이 중요합니다. 민감 코드가 많다면 마스킹, 프록시, 정책 정리가 선행돼야 합니다.
6. 기존 모델·도구와 비교: 언제 이득인가
Claude 3 / Opus 4.1 / 4.6 대비
Claude Opus 4.7 코딩 성능의 업그레이드는 짧은 스니펫보다 복잡한 멀티파일 작업에서 더 잘 보입니다. 외부 자료에서는 SWE-bench Pro 64.3%로 소개되며, 비교 자료는 특히 장기 에이전트와 tool use 강화를 포인트로 잡습니다.
반대로 짧은 자동완성이나 단순 알고리즘 풀이만 한다면 체감 차이는 작을 수 있습니다. 이미 현재 도구가 그 일을 충분히 잘하고 있다면 교체 이유는 약해집니다.
Copilot·Cursor 대비
| 항목 | Claude Opus 4.7 | Copilot/Cursor 계열 |
|---|---|---|
| 긴 컨텍스트 이해 | 강점 | 보통~강점 |
| 인라인 자동완성 속도 | 보통 | 강점 |
| 설계 토론·리팩토링 계획 | 강점 | 상대적 약점 |
| 에이전트형 루프 | 강점 | 도구별 차이 큼 |
| IDE 깊은 통합 | 보통 | 강점 |
즉, Copilot이나 Cursor는 손 가까이에 있는 빠른 보조 도구에 가깝고, Claude Opus 4.7 코드 리팩토링 에이전트는 긴 설계 대화와 구조 개선에 더 강합니다. 현실적으로는 둘 중 하나만 고르기보다 역할을 분리해 함께 쓰는 편이 좋습니다.
7. 실전 도입 가이드
도입 전 체크리스트
성능이 좋아도 아무 팀에나 바로 맞는 것은 아닙니다. 먼저 아래 질문이 정리돼야 합니다.
- 외부 LLM에 보낼 수 있는 코드 범위가 정해져 있는가
- 주력 스택이 Java, TypeScript, Python 같은 메이저 영역인가
- 현재 병목이 기능 개발, 코드 리뷰, 레거시 개선, 장애 대응 중 어디인가
목적 없는 도입은 대부분 흐지부지됩니다. 반대로 병목이 분명한 팀은 효과 검증도 훨씬 쉽습니다.
2주 시범 도입 설계
작은 PoC가 가장 좋습니다. 목표는 한 문장으로 명확해야 합니다. 예를 들면 PR 리뷰 시간을 줄이되 리뷰 깊이는 유지한다처럼 잡는 식입니다. 수치 목표는 외부 평균보다 팀 내부 기준으로 잡는 편이 안전합니다.
| 그룹 | 방식 | 측정 포인트 |
|---|---|---|
| A | 기존 방식 유지 | PR 리드타임, 리뷰 코멘트 유형 |
| B | Claude Opus 4.7 코드 리팩토링 에이전트 활용 | 리드타임, 회귀 버그, 만족도 |
프롬프트와 운영 원칙
- 목표를 먼저 준다.
- 핵심 파일만 준다.
- 팀 규칙과 금지 사항을 상단에 쓴다.
- 계획 수립과 코드 생성을 분리한다.
- 최종 판단은 사람이 한다.
이 원칙만 지켜도 결과 품질은 크게 올라갑니다. 모델은 시니어 리뷰어 + 주니어 코더처럼 활용하고, 설계 책임과 보안 책임은 여전히 사람이 가져가야 합니다.
8. 장단점 총정리와 추천 시나리오
장점
Claude Opus 4.7 코딩 성능의 핵심 장점은 대규모 코드베이스 이해, 긴 컨텍스트 처리, 복잡한 문제 분해 능력입니다. 외부 자료 기준으로 CursorBench 70%, SWE-bench Pro 64.3% 같은 수치가 이를 뒷받침합니다. 또한 장기 세션과 tool use를 묶어 반복 작업을 맡기기 좋다는 점도 큽니다. Risemoment 분석은 이런 특성을 실무 생산성과 연결해 설명합니다.
단점과 주의점
환경 의존 버그, 희귀 프레임워크, 긴 세션 혼선은 여전히 약점입니다. 보안과 프라이버시 이슈도 무시하기 어렵습니다. 또 모델 의존이 과해지면 팀 내부 도메인 지식이 문서화되지 않고 답변에만 기대게 될 수 있습니다.
그래서 모델이 만든 결과를 설명하고 공유하는 문화가 필요합니다. 모델은 작업을 가속하지만, 책임의 주체를 대체하지는 않습니다.
특히 추천하는 팀
- PR과 코드 리뷰가 큰 병목인 팀
- 레거시 코드를 점진적으로 개선해야 하는 조직
- 이미 AI 코딩 도구를 쓰고 있고 다음 단계로 가고 싶은 팀
결론: 의사결정 체크리스트
Claude Opus 4.7 개발자 후기와 공개 자료를 종합하면, 이 모델은 짧은 자동완성보다 긴 맥락 이해, 리뷰, 리팩토링, 디버깅에서 더 큰 가치를 줍니다. 결국 핵심은 더 똑똑한 자동완성이냐가 아니라, 실무 워크플로우에 들어가는 에이전트로 볼 수 있느냐입니다.
- 코드 리뷰·리팩토링 시간이 매우 큰 비중을 차지한다
- 팀 주력 스택이 메이저 언어·프레임워크다
- 외부 LLM 사용에 대한 정책과 합의가 있다
- 기존 도구로는 설계·리팩토링 지원이 부족하다고 느낀다
체크가 많을수록 도입 가치가 큽니다. 2개 정도라면 PR 리뷰 보조부터 부분 도입이 좋고, 1개 이하라면 내부 정책과 워크플로우를 먼저 정리한 뒤 검토하는 편이 낫습니다.
자주 묻는 질문 (FAQ)
Claude Opus 4.7 코딩 성능은 기존 AI 코딩 도구보다 무조건 좋나요?
무조건 그렇지는 않습니다. 짧은 자동완성이나 단순 코드 생성만 보면 다른 도구와 체감 차이가 크지 않을 수 있습니다. 다만 멀티파일 이해, PR 리뷰, 디버깅, 레거시 개선처럼 긴 문맥이 필요한 작업에서는 장점이 더 뚜렷합니다.
Claude Opus 4.7 코드 리팩토링 에이전트로 실제 투입할 때 가장 중요한 원칙은 무엇인가요?
가장 중요한 원칙은 자동 적용보다 자동 제안과 사람 승인 구조를 유지하는 것입니다. 팀 규칙, 금지 사항, 목표를 먼저 명시하고 계획 수립과 코드 생성을 분리하면 결과 품질이 더 안정적입니다.
Claude Opus 4.7 개발자 후기는 대체로 어떤 평가가 많나요?
대체로 코딩 벤치마크 개선, 긴 세션 안정성, 코드 리뷰와 리팩토링 지원 측면에서 긍정적입니다. 반면 희귀 스택 대응력, 환경 의존 버그, 보안 정책 문제는 한계로 자주 언급됩니다.
도입 전 PoC는 얼마나 작게 시작하는 것이 좋나요?
보통 2주 정도의 작은 PoC가 적당합니다. PR 리뷰 보조나 레거시 모듈 하나처럼 범위를 좁혀서, 리드타임과 회귀 버그, 팀 만족도를 함께 비교하는 방식이 가장 실용적입니다.
“Claude Opus 4.7 코딩 성능 실무 리팩토링 활용과 평가”에 대한 2개의 생각